京东云语音语义领域8篇论文被国际顶会发表
技术的价值往往体现在其应用过程中,便随着人工智能的大规模应用,人工智能的工程化能力正在被人们所关注,根据Gartner发布的2021年重要战略科技趋势,为将人工智能转化为生产力,就必须转向人工智能工程化这门专注于各种人工智能操作化和决策模型(例如机器学习或知识图)治理与生命周期管理的学科。
那么,人工智能的基础研究不再重要了吗?
答案是否定的。纵观全球各科技企业,无不例外在持续加大对人工智能基础研究的投入,以语音语义为例,作为人工智能的重要组成部分,对该领域的研究正不断突破,为人机的交互模式带来了更多的可能。
2021年,京东云横扫多个国际顶级学术会议,多篇论文获被发表,细分领域跨域长文的机器阅读理解、内容生成、知识融合、对话推荐、图神经网络和可解释的增量学习等。
下面以其中的8篇论文为例,分享各自在解决所要攻克的问题、提出的新方法以及取得的可被行业借鉴的成果。?
论文标题:RoR: Read-over-Read for Long Document Machine Reading Comprehension
论文链接: of EMNLP 2021
Motivation: 大规模预训练语言模型在多个自然语言处理任务上取得了显著的成果,但受限于编码长度(例如,BERT只能一次性编码512个WordPiece字符),无法有效地应用于多种长文本处理任务中,例如长文本阅读理解任务。
Solution:?对此,本论文提出了从局部视角到全局视角的重复阅读方法RoR(如下图所示),可提高超长文本的阅读理解能力。具体而言,RoR?包括一个局部阅读器和一个全局阅读器。首先,给定的长文本会被切割为多个文本片段。然后,局部阅读器会为每个文本片段预测出一组局部答案。这些局部答案接下来会被组装压缩为一个新的短文本来作为原始长文档的压缩版本。全局阅读器会进一步从此压缩文本中预测出全局答案。最终,RoR使用一种投票策略来从局部和全局答案中选择最终预测。
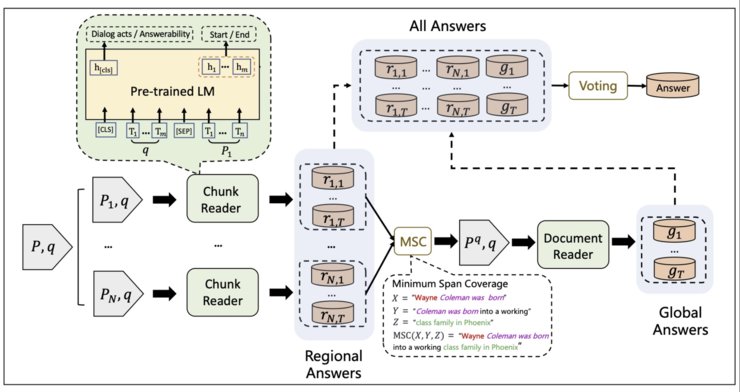
Experimental Result:在两个长文本阅读理解基准?QuAC?和?TriviaQA?上,大量实验证明了RoR可以有效提高预训练语言模型在长文档阅读的建模能力。RoR在公开对话阅读理解榜单QuAC( src="http://p1.qhimgs4.com/t0107f7df3440624844.jpg">
图1:QuAC官方Leaderboard(截止2021/10)
论文标题:Learn to Copy from the Copying History: Correlational Copy Network for Abstractive Summarization
发表刊物:EMNLP 2021
Motivation: 复制机制是生成式自动文摘模型的常用模块,已有模型使用注意力概率作为复制概率,忽视了复制历史的影响。
Solution: 本论文提出了一种新的复制机制(Correlational Copying Network,CoCoNet),该机制可以使用复制历史指导当前的复制概率。具体来说,CoCoNet在计算每一步的复制概率时,不仅会参考当前时刻的注意力概率,还会通过相似度和距离度量,将历史时刻的复制概率转移到当前时刻,从而提高复制行为的连贯性和合理性。此外,我们还提出一种Correlational Copying Pre-training (CoCo-Pretrain) 子任务,进一步增强CoCoNet的复制能力。
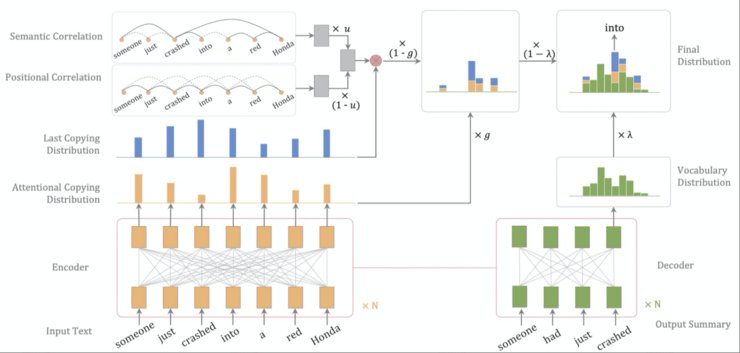
Experimental Result:本论文提出的复制机制,可以应用于一系列文本摘要相关应用中。我们在新闻摘要数据集(CNN/DailyMail?dataset)和对话摘要数据集(SAMSum?dataset)上的效果(如表1、2)超过已有的生成式摘要模型。
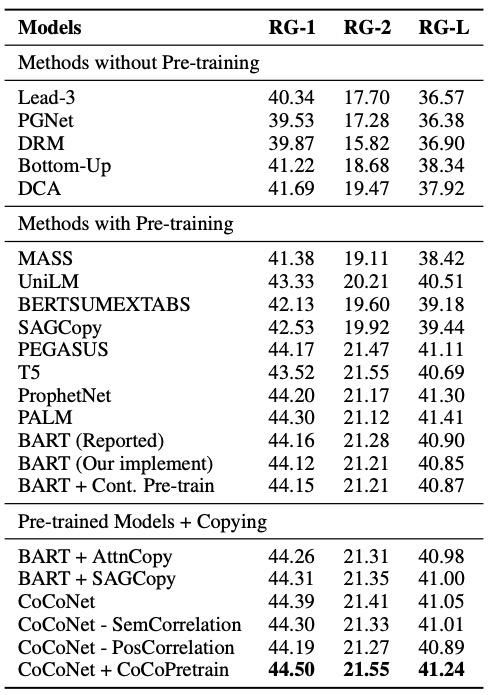
表1:ROUGE scores on the CNN/DailyMail?dataset.
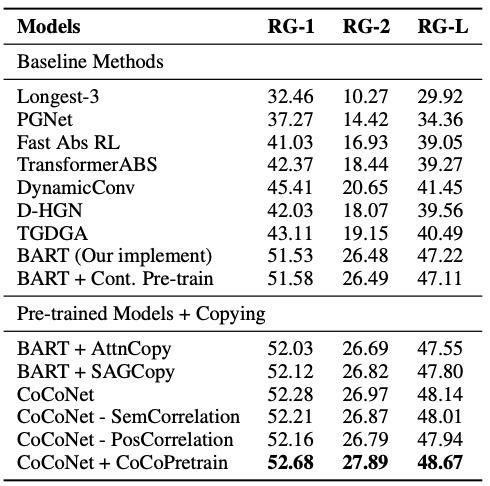
表2:ROUGE scores on the?SAMSum?dataset.
论文标题:K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce
论文链接: of EMNLP 2021
Motivation: 预训练语言模型在多个NLP任务展示出超越非训练语言模型的效果。然而,预训练语言模型在领域迁移过程中,性能会受到影响。特定领域的预训练语言模型对该领域的下游应用会有很大帮助。
Solution: 本论文为电商领域设计了一个大规模预训练语言模型,定义了一系列电商领域知识,包括产品词、商品卖点、商品要素和商品属性。并针对这些知识,提出了相应的语言模型预训练任务,包括面向知识的掩码语言模型、面向知识的掩码序列到序列生成、商品实体的要素边界识别、商品实体的类别分类、商品实体的要素摘要生成。
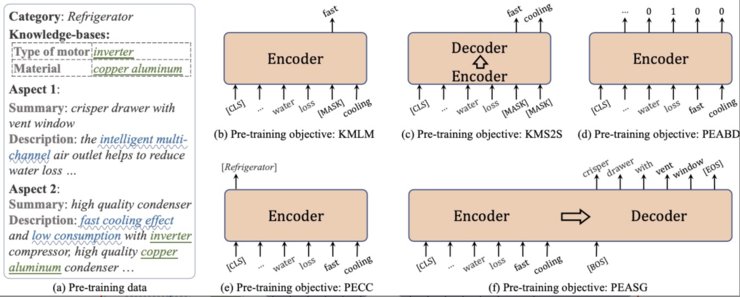
Result:本论文提出的预训练语言模型可应用于多个电商领域的文本理解和生成任务,在包括电商知识图谱补齐、电商客服多轮对话、商品自动文摘等多个任务上取得最佳性能。
文章来源:《国际研究参考》 网址: http://www.gjyjck.cn/zonghexinwen/2021/1017/1186.html